Hive
hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供完整的sql查询功能,可以将sql语句转换为MapReduce任务进行运行。其优点是学习成本低,可以通过类SQL语句快速实现简单的MapReduce统计,不必开发专门的MapReduce应用,适合数据仓库的统计分析
Hwi
Hwi是Hive Web Interface的简称,是Hive Cli的一个web替代查询工具(Hive提供的服务接口)
部署
因为工作需要,原本我们需要通过Hive查询数据都要通过ssh连接远程服务器上启动Hive Cli进行操作,老大正好分配让我去完成一个Hive 在线查询的功能
第一个方案是通过hue来完成这个需求(但是hue太大了,hive编辑查询器只是其中的一个小功能,并且部署到服务器上之后,一些配置的问题至今都没想到方法去解决),所以股弄了两三天就放弃了这个方案
Hue是一个开源的Apache Hadoop UI系统
第两个方案就是通过hwi来完成,因为本身hive就提供了hwi的源码包:
- hive-hwi-0.14.0.jar — hive服务接口jar包
- hive-hwi-0.14.0.war — hwi ui webapp
当然真正的运行hwi,还得依赖${HIVE_HOME}/lib下的其他依赖包,在0.14.0版本之前可能还需要加入JDK中的tools.jar
Hwi安装配置
首先,保证Hadoop服务与Hive启动并且正常运行
因为之后我需要对hwi中的war包进行重新修改编译,所以这里需要配置下Ant
下载Ant包解压之后,在${HIVE_HOME}/conf/hive-env.sh文件中,配置如下:
export ANT_LIB=/usr/local/ant(ant安装目录)
加入如下jar包:
// 用于编译JSP文件
jasper-compiler-5.5.23.jar
jasper-runtime-5.5.23.jar
//tomcat7/lib下面的servlet-api.jar文件
servlet-api.jar
可能版本的问题,需要将JDK下的tools.jar加入到${HIVE_HOME}/lib中
为了我们看到Web效果,在${HIVE_HOME}/conf/hive-site.xml配置文件中,配置如下:
<!-- Hwi 配置 -->
<property>
<name>hive.hwi.listen.host</name>
<value>0.0.0.0</value>
</property>
<property>
<name>hive.hwi.listen.port</name>
<value>9999</value>
</property>
<property>
<name>hive.hwi.war.file</name>
<value>/lib/hive-hwi-0.14.0.war</value>
</property>
启动Hwi服务:./${Hive_Home}/bin/hive –service hwi
打开浏览器输入:http://0.0.0.0:9999/hwi 就可以看到首页了
改造
配置好了之后,可以去体验是怎样操作完成一个HQL查询功能
我对hwi的原理理解:
获取你输入的信息(SQL语句),拿到信息之后就在hive服务中执行(相当于在终端服务中执行SQL,可能伴随进行MapReduce过程),最后将结果返回给你
虽然原始的hwi功能完整,但是查询的体验感不行,给我的感觉就是太繁琐,输入的帐号用户过多,并且查询结果不能实时的显示(没有实时记录,文件不支持下载等)
所以只好自己动手起来整理修改啦
解压hive-hwi-0.14.0.war包
由于我不想重新修改编译hive-hwi-0.14.0.jar代码与结构,所以只能在jsp中嵌入java逻辑了
实现的业务细节我就不详谈了(下面我把修改后的项目使用图贴出来,就可以知道怎么实现的了)
在这提一点就是使用jetty搭建简单文件服务器
因为我是将查询结果放入文件中(默认以当前时间戳为临时文件名),如果查询结果不超过100kb允许在页面中实时显示结果
可是怎么实现文件下载功能呢?
使用jetty完成文件服务器的功能,引入如下jar包(加入到$(HIVE_HOME)/lib,并且下面编译代码的时候也需要这些jar包,需要指定路径):
// 用于文件服务器
jetty-continuation-8.1.0.RC5.jar
jetty-io-8.1.0.RC5.jar
jetty-server-8.1.0.RC5.jar
jetty-util-8.1.0.RC5.jar
jetty-xml-8.1.0.RC5.jar
jetty-http-8.1.0.RC5.jar
jetty-security-8.1.0.RC5.jar
jetty-servlet-8.1.0.RC5.jar
jetty-webapp-8.1.0.RC5.jar
具体代码实现参考:hwi文件服务器的搭建
需要注意的一点就是文件内容的乱码问题,解决方案如下:
在JettyFileServer类中添加如下代码:
HandlerWrapper wrapper = new HandlerWrapper() {
@Override
public void handle(String target, Request baseRequest, HttpServletRequest request, HttpServletResponse response)
throws IOException, ServletException {
super.handle(target, baseRequest, request, response);
}
};
//添加处理器,多个处理器的情况下会依次处理
Handler coding = new CodingHandler();
wrapper.setHandler(coding);
HandlerList handlers = new HandlerList();
handlers.setHandlers(new Handler[] { wrapper });
createFileServerContexts(handlers);
handlers.addHandler(new DefaultHandler());
//实现一个编码处理器类
public static class CodingHandler extends AbstractHandler {
public void handle(String target,Request baseRequest,HttpServletRequest request,HttpServletResponse response)
throws IOException, ServletException
{
response.setContentType("text/html;charset=utf-8");
}
}
部署的话,使用javac -cp ../所有依赖jar包 xxx.java编译成对应.class文件
之后可以将整个服务器代码(实际就三个类文件)打包成一个filejettyserver.jar添加到${HIVE_HOME}/lib路径下
至此整个项目就完成了
项目效果
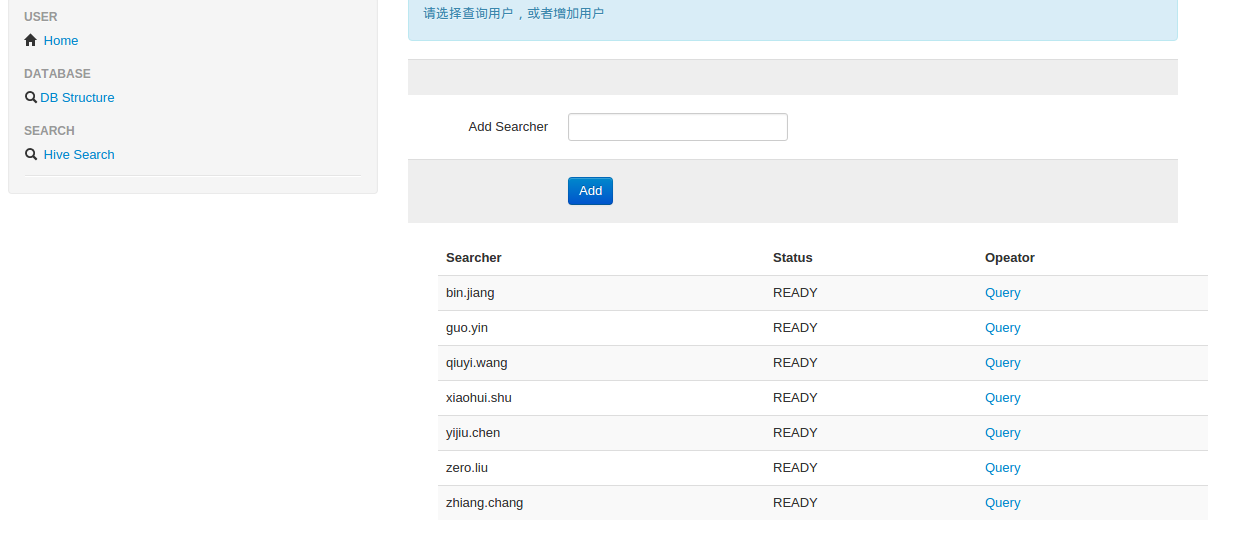
1.进入主页,添加查询用户,或者从已有列表中选择一个用户进行查询
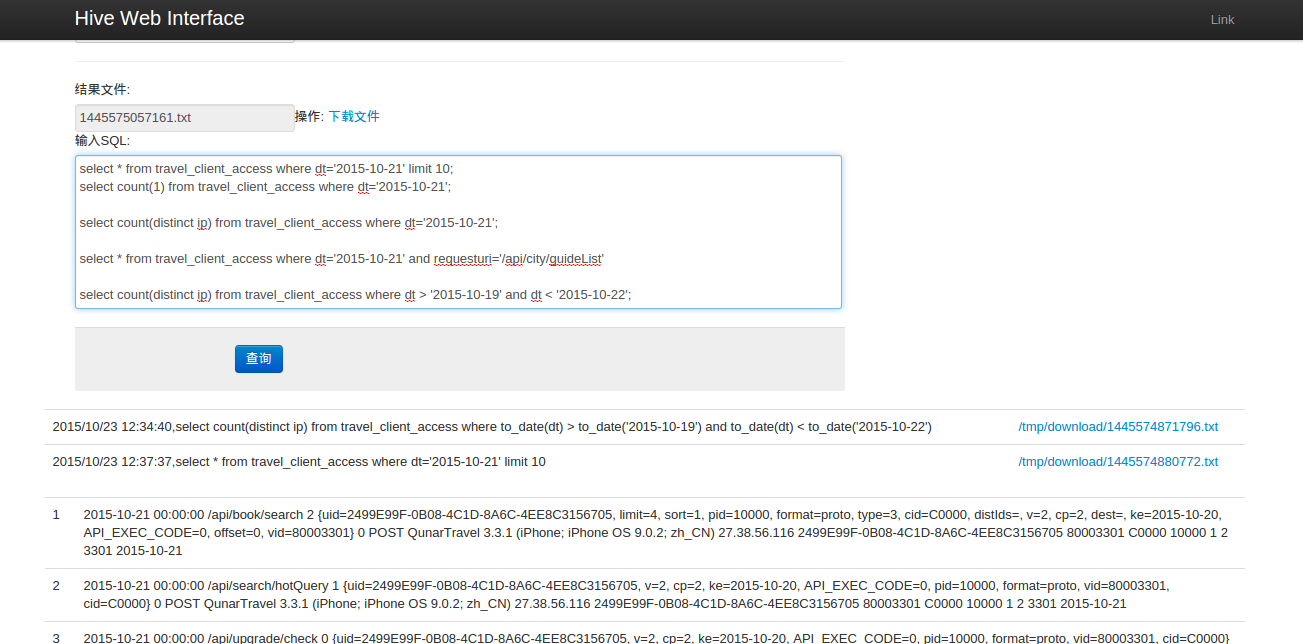
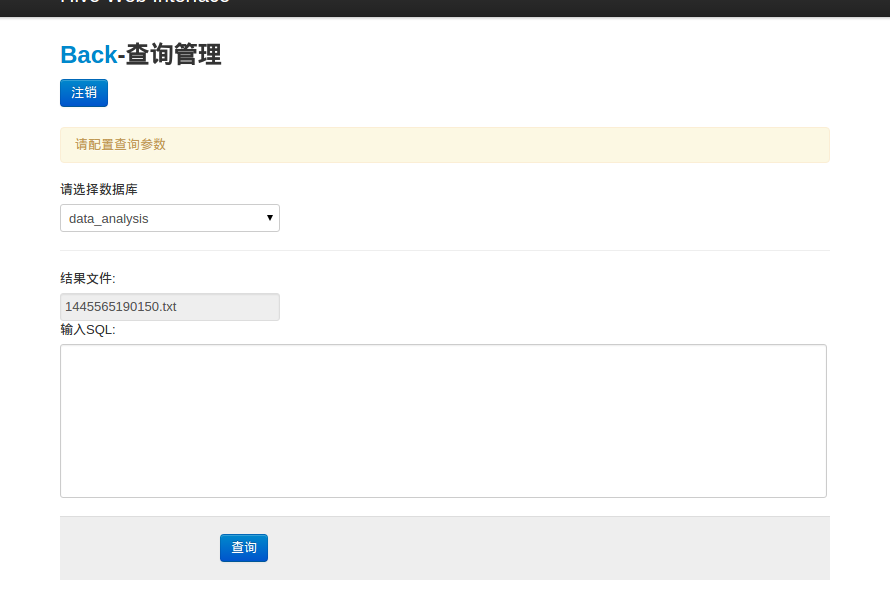
2.选择用户进入查询界面,选择操作数据库,输入SQL查询语句(不用输 use “database”,你选择数据库之后就已经存在这条语句了),提交之后等待查询计划完成(如果执行mapreduce过程可能等待时间比较漫长)
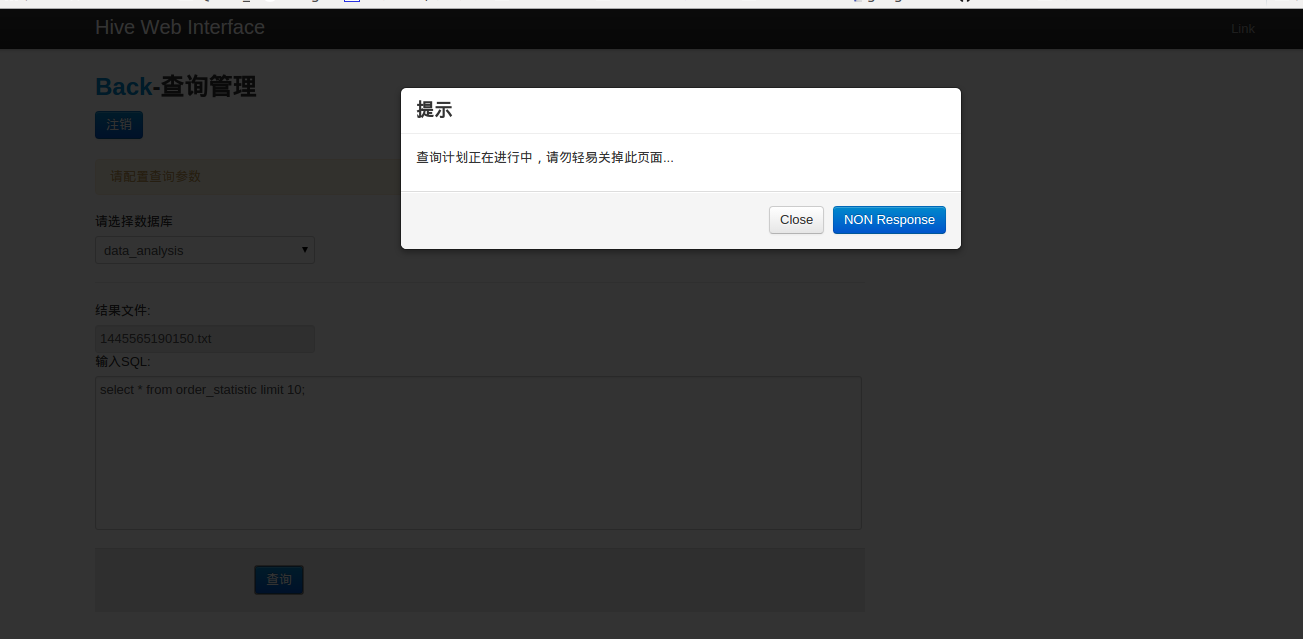
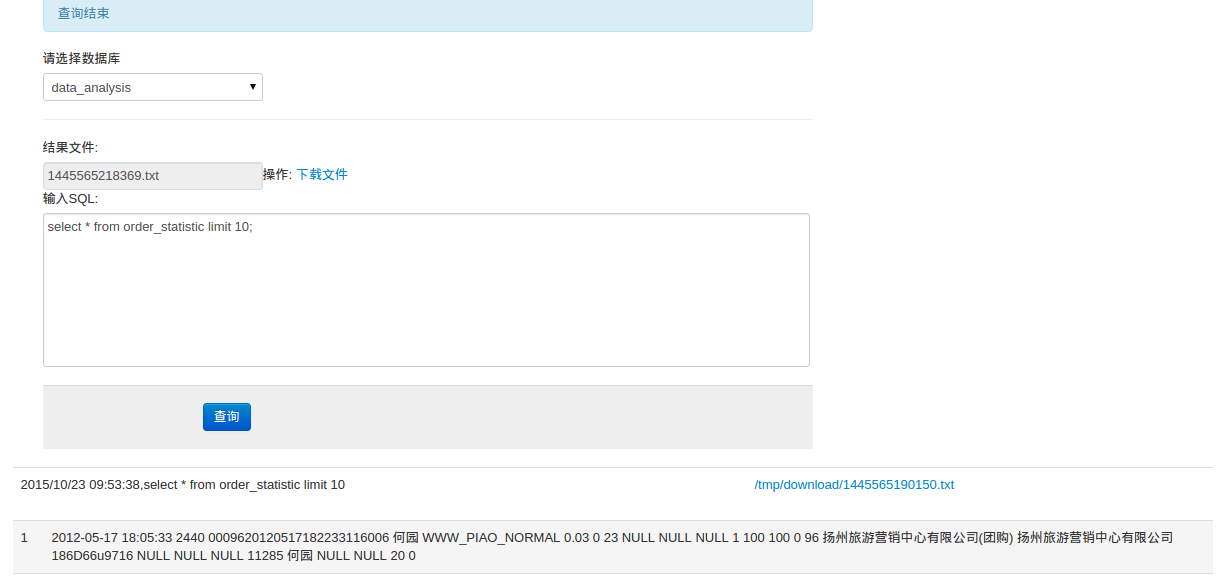
3.等查询完成后,页面会刷新,在下方会出现查询历史记录(最近6条)以及查询结果(也会写入到文件中,如果查询结果大于100kb则不在页面中显示可以在文件中查看)

4.如果需要选择其他用户,上方有一个注销按钮(代表退出当前用户,点Back只是返回首页,但是用户还是没有退出)
5.多条查询效果